Intelligenza artificiale e machine learning nella cybersecurity
Arthur Samuel, pioniere nel campo dell'intelligenza artificiale, ha descritto l'IA come un insieme di metodi e tecnologie che "conferisce ai computer la capacità di apprendere senza essere esplicitamente programmati". Nel caso specifico del supervised learning (apprendimento supervisionato) per soluzioni anti-malware, il task in questione si potrebbe formulare nel modo seguente: dato un insieme \( X \) di caratteristiche dell'oggetto, e fornite in qualità di input le corrispondenti etichette \( Y \) dell'oggetto, si crei un modello in grado di produrre le etichette corrette \( Y' \) per gli oggetti da testare \( X' \) non individuati in precedenza. \( X \) potrebbe riferirsi ad alcune caratteristiche che rappresentano il contenuto o il comportamento del file (statistiche del file, elenco delle funzioni API utilizzate e così via), mentre le etichette \( Y \) potrebbero essere semplicemente "malware" o elementi "benigni" (nei casi più complessi, potremmo essere interessati a una classificazione maggiormente dettagliata, come Virus, Trojan-Downloader, Adware e così via). In caso di unsupervised learning (apprendimento non supervisionato), siamo invece più interessati a rivelare le strutture nascoste dei dati, individuando ad esempio gruppi di oggetti simili o caratteristiche altamente correlate.
La protezione multilivello Next Generation di Kaspersky utilizza approcci di IA, come le tecniche di machine learning in tutte le fasi della pipeline di rilevamento: si va dai metodi di clustering scalabili utilizzati per la pre-elaborazione del flusso dei file in entrata ai modelli di rete neurale solidi e compatti dedicati all'analisi comportamentale, in grado di funzionare direttamente sui dispositivi degli utenti. Queste tecnologie sono progettate per soddisfare diversi requisiti importanti per le applicazioni di cybersecurity nel mondo reale, tra cui un tasso di falsi positivi estremamente basso, l’interpretabilità dei modelli e la robustezza contro gli avversari.
Esamineremo, qui di seguito, alcune delle più importanti tecnologie, basate su machine learning, utilizzate nei prodotti endpoint di Kaspersky.
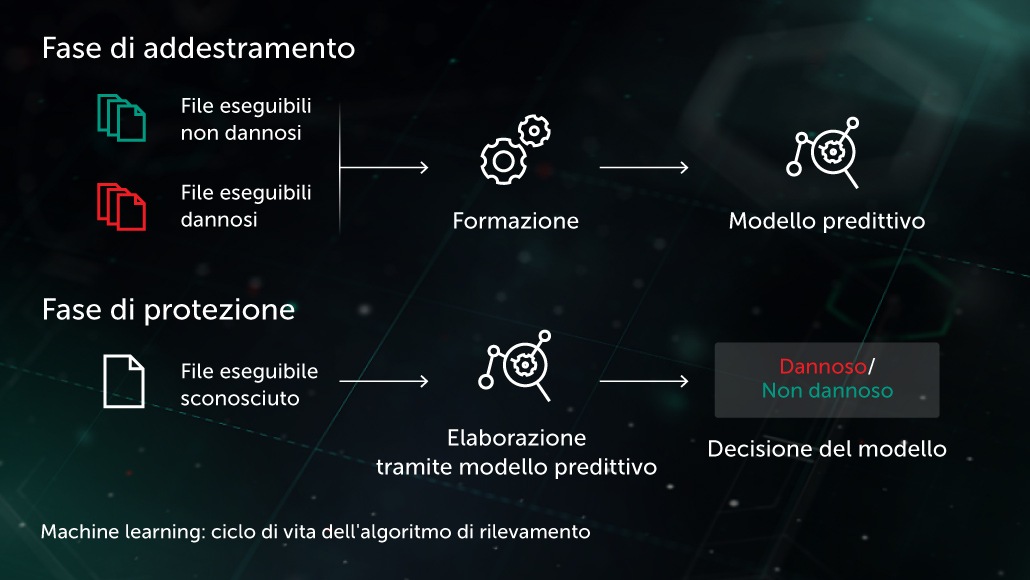
Ensemble di decision tree
Con un simile approccio, il modello predittivo assume la forma di un insieme di decision tree (ad esempio, random forest o gradient boosted trees). Ogni "nodo non foglia" di un albero contiene una domanda riguardante le caratteristiche di un file, mentre i "nodi foglia" contengono la decisione finale dell'albero relativamente all'oggetto. Durante la fase di test, il modello percorre l'albero rispondendo alle domande presenti nei nodi che evidenziano le caratteristiche corrispondenti all'oggetto preso in esame. Nella fase finale, le decisioni di più alberi vengono mediate in base a uno specifico algoritmo, in modo da fornire la decisione finale sull'oggetto.
Sul sito dell'endpoint il modello beneficia di una fase di protezione proattiva pre-esecuzione. Una delle applicazioni da noi implementate riguardo a tale tecnologia è rappresentata dalla soluzione Cloud ML for Android, utilizzata per il rilevamento delle minacce mobili..
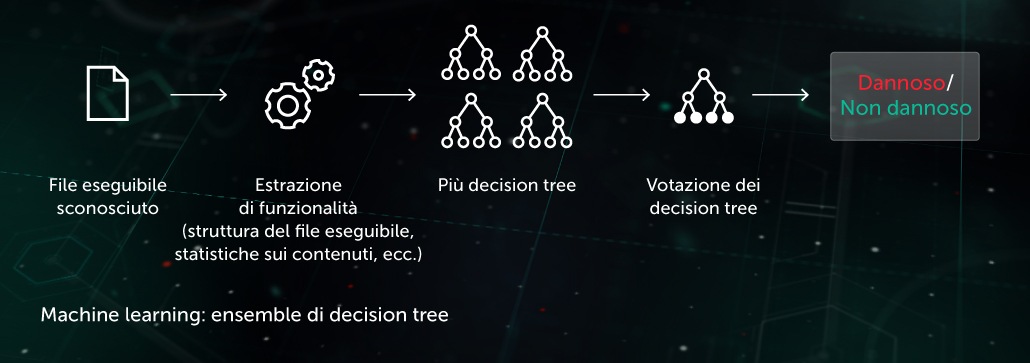
Similarity Hash (hash sensibili alla posizione)
In passato, gli hash utilizzati per creare “impronte” di malware erano sensibili a ogni piccola modifica in un file. Questo svantaggio è stato sfruttato dai creatori del malware tramite tecniche di offuscamento come il polimorfismo lato server: modifiche minori nel malware per renderlo invisibile ai radar. Attualmente, si utilizza il metodo IA Similarity Hash (ovvero hash sensibili alla posizione) per rilevare file dannosi di tal genere. Per fare ciò, il sistema estrae le caratteristiche del file e utilizza il learning basato sulla proiezione ortogonale per scegliere le caratteristiche più importanti. In seguito viene applicata la compressione basata su ML, in modo che i vettori di valore inerenti a tali caratteristiche vengano trasformati in modelli simili o identici. Questo metodo fornisce una buona generalizzazione e riduce considerevolmente le dimensioni del database dei record di rilevamento, visto che con un solo record è ora possibile rilevare un'intera famiglia di malware polimorfico.
Sul sito dell'endpoint il modello beneficia di una fase di protezione proattiva pre-esecuzione. Viene applicato nell'ambito del nostro Similarity Hash Detection System.
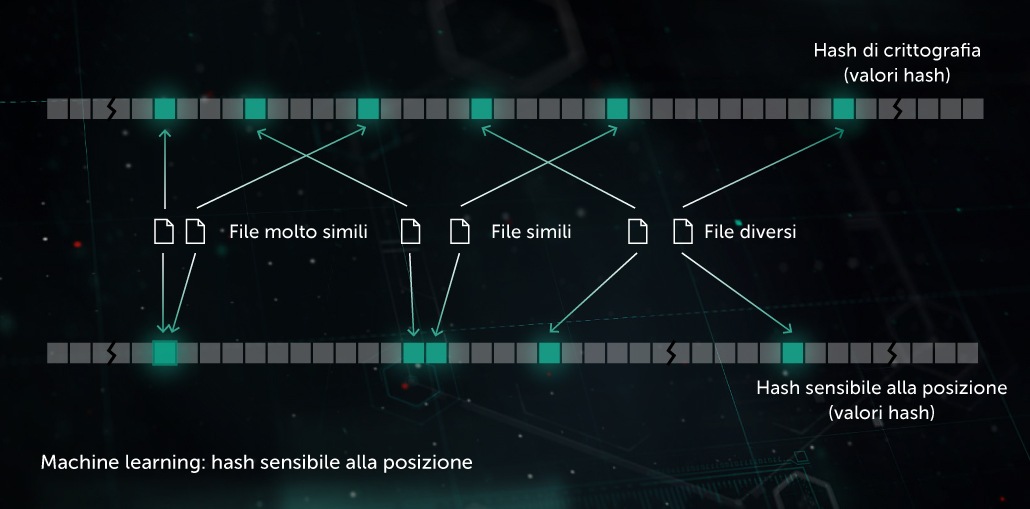
Modello comportamentale
Un componente adibito al monitoraggio fornisce un log relativo al comportamento, ovvero la sequenza degli eventi di sistema verificatisi durante l'esecuzione del processo, unitamente agli argomenti corrispondenti. Al fine di rilevare attività dannose nell'ambito dei dati inerenti al log osservato, il nostro modello comprime la sequenza degli eventi ottenuta in un insieme di vettori binari e addestra la rete neurale profonda perché si possano distinguere i log puliti da quelli dannosi.
La classificazione degli oggetti effettuata dal Modello comportamentale viene utilizzata dai moduli di rilevamento statico e dinamico presenti nei prodotti Kaspersky sul lato endpoint.
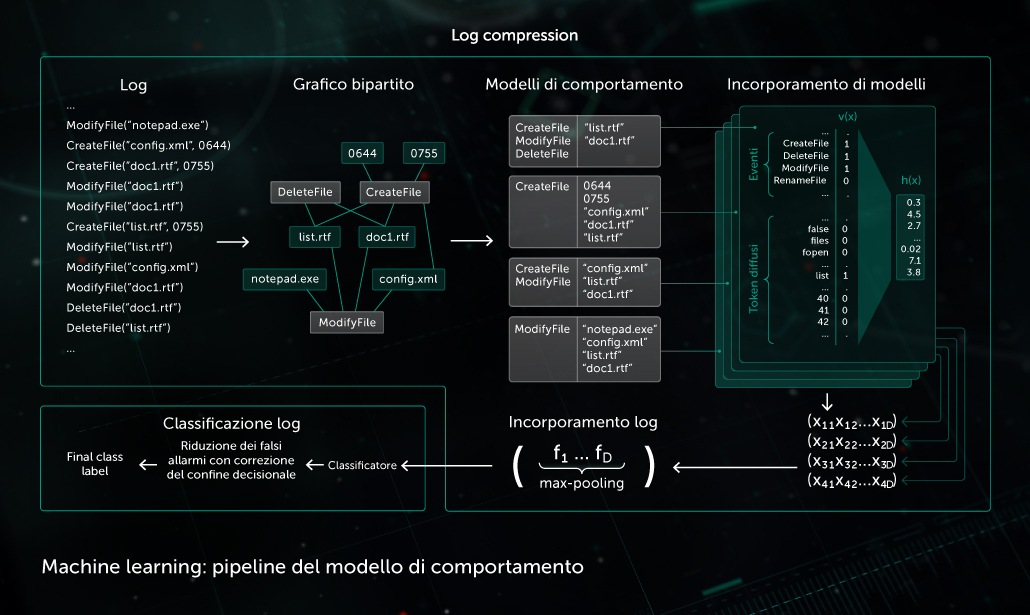
L’intelligenza artificiale svolge anche un ruolo altrettanto importante nella creazione di un’adeguata infrastruttura di elaborazione del malware in laboratorio. Viene utilizzato da Kaspersky per i seguenti scopi infrastrutturali:
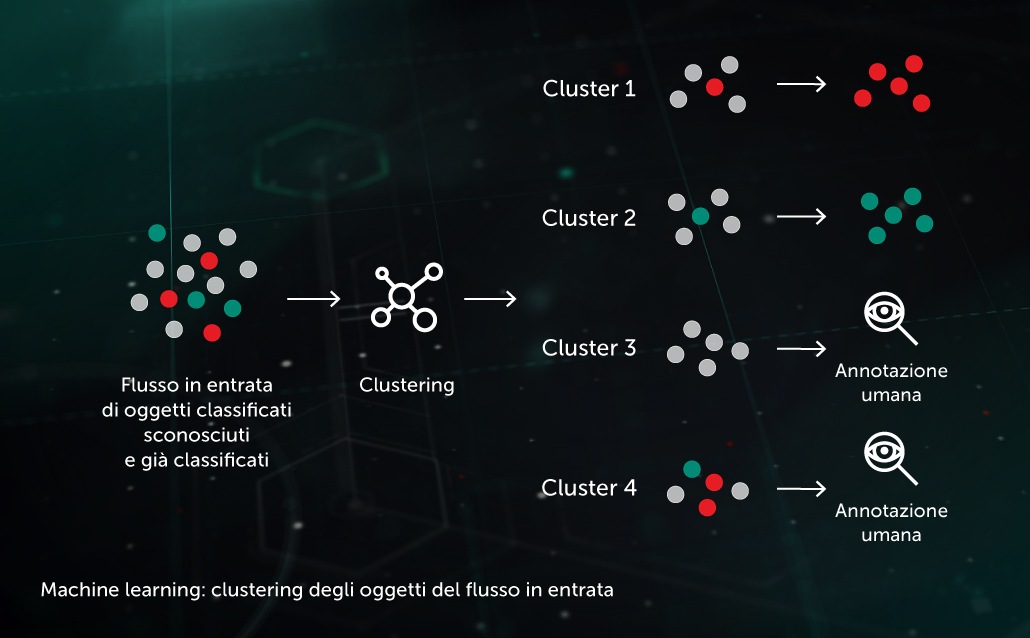
Clustering dei flussi in entrata
Gli algoritmi di clustering basati su ML ci consentono di separare in modo efficiente i grandi volumi di file sconosciuti che giungono alla nostra infrastruttura in un numero ragionevole di cluster, alcuni dei quali si possono elaborare automaticamente in base alla presenza di un oggetto già annotato all'interno di essi.
Modelli di classificazione su larga scala
Alcuni dei più potenti modelli di classificazione (quali un'enorme foresta di decisioni casuali) richiedono significative quantità di risorse (tempo del processore, memoria) e costosi estrattori di funzionalità (potrebbe ad esempio essere richiesta l'elaborazione tramite sandbox per ottenere log di comportamento particolarmente dettagliati). Si rivela pertanto di maggiore efficacia mantenere ed eseguire i modelli in un laboratorio, per poi distillare le conoscenze acquisite attraverso tali modelli mediante l'addestramento di un modello di classificazione leggero, in base alle decisioni di output relative al modello più esteso.
Sicurezza nell'uso degli aspetti ML dell'intelligenza artificiale
Gli algoritmi ML, una volta oltrepassati i confini del laboratorio nel mondo reale, potrebbero rivelarsi vulnerabili a molte forme di attacchi progettati per costringere i sistemi IA a commettere errori in modo deliberato. L'autore dell'attacco può ad esempio "avvelenare" un set di dati di addestramento o eseguire il reverse engineering del codice del modello. Inoltre, gli hacker possono applicare la forza bruta ai modelli ML con l’aiuto di sistemi di "IA antagonista" appositamente sviluppatiche possono generare automaticamente molti campioni di attacco e lanciarli contro la soluzione protettiva o il modello ML estratto fino a scoprire un punto debole del modello. L'impatto di simili attacchi sui sistemi anti-malware che utilizzano l'IA potrebbe rivelarsi devastante: l'errata identificazione di un Trojan può in effetti significare milioni di dispositivi infetti e milioni di dollari persi.
Per questo motivo, ci sono alcune considerazioni chiave da applicare quando si utilizza l'IA nei sistemi di sicurezza:
- Il vendor di soluzioni di sicurezza dovrebbe ben comprendere quali siano i requisiti essenziali per le performance degli elementi IA nel mondo reale, potenzialmente ostile, valutandoli con la massima attenzione; tali requisiti comprendono, ad esempio, una buona dose di solidità ed efficacia nei confronti dei potenziali avversari. I controlli di sicurezza e il "red-teaming" specifici IA/ML dovrebbero essere componenti chiave nello sviluppo di sistemi di sicurezza che utilizzano aspetti dell’intelligenza artificiale.
- Quando valutate la sicurezza di una soluzione che utilizza elementi di intelligenza artificiale, chiedete in che misura la soluzione dipende da dati e architetture di terze parti, poiché molti attacchi si basano su input di terze parti (stiamo parlando di feed di intelligence sulle minacce, set di dati pubblici, modelli di intelligenza artificiale pre-addestrati ed esternalizzati).
- I metodi ML/IA non dovrebbero essere visti come una soluzione miracolosa: devono essere parte di un approccio alla sicurezza a più livelli, in cui tecnologie di protezione complementari e competenze umane collaborano, proteggendosi a vicenda.
È importante riconoscere che, sebbene Kaspersky abbia una vasta esperienza nell'uso efficiente di aspetti dell'intelligenza artificiale come le tecniche di machine learning e il suo sottoinsieme Deep Learning nelle soluzioni di cybersecurity, queste tecnologie non sono vera intelligenza artificiale o intelligenza generale artificiale (AGI). C’è ancora molta strada da fare prima che le macchine possano funzionare in modo indipendente ed eseguire la maggior parte dei compiti in modo completamente autonomo. Fino ad allora, quasi ogni aspetto dell’intelligenza artificiale nella cybersecurity richiederà la guida e l’esperienza di professionisti umani per sviluppare e perfezionare i sistemi, aumentandone le capacità nel tempo.
Per avere una panoramica più dettagliata degli attacchi maggiormente diffusi nei confronti degli algoritmi ML/IA dei metodi di protezione da simili minacce, consultare il nostro whitepaper "AI under Attack: How to Secure Artificial Intelligence in Security Systems".
Related Products

Tecnologie correlate
 Whitepaper
Whitepaper
WhitepaperMachine Learning for Malware Detection
Whitepaper
WhitepaperMachine learning and Human Expertise
Whitepaper
WhitepaperAI under Attack: How to Secure Machine Learning in Security System