 backup
backup
Contrariamente alla credenza popolare che qualsiasi cosa online rimanga online, Internet non ricorda proprio tutto. In un post precedente di questa serie abbiamo esaminato non meno di nove scenari di perdita dell’accesso ai contenuti online. Abbiamo inoltre fornito una dettagliata guida su quali informazioni includere in un backup nel computer (e preferibilmente in modo rapido) e su come procedere. Oggi vedremo come salvare facilmente le pagine Web nel proprio computer, come organizzare questi archivi e cosa fare se un sito preferito è sparito dalla circolazione.
Supponiamo di voler salvare un post di un blog, compilare una bibliografia o addirittura preservare un’intera specifica pubblicazione online a scopi legali. Quando tutto questo prende la forma online di pagine Web, ha spesso la tendenza a scomparire nel momento sbagliato. Vuoi tuffarti nelle notizie musicali e nei pettegolezzi del 2005? Auguri: il sito MTV News è stato chiuso e tutti i suoi articoli e interviste non sono più disponibili. E i collegamenti negli articoli di Wikipedia? L’11% non porta da nessuna parte anche se funzionavano quando l’articolo è stato pubblicato. Questo fenomeno dei “link andati a male”, la graduale eliminazione o ricollocazione dei contenuti online, sta rapidamente diventando un grave problema. Oggi infatti non è più accessibile il 38% delle pagine che esistevano dieci anni fa. Quindi, se una pagina Web ci piace o ci serve in modo particolare, sarebbe saggio crearne una copia di backup.
Come salvare una pagina Web nel computer
Poiché una pagina Web è composta da decine o centinaia di file, il backup richiederà un po’ di sforzo. Ecco i modi principali per farlo:
Salvare solo il testo come file HTML. Seleziona il comando o il pulsante di menu “Salva pagina con nome…” nel browser, quindi seleziona “Pagina Web, solo HTML”. Questo salverà solo il testo della pagina Web, senza elementi grafici o altri abbellimenti.
Salvare testo e immagini. L’opzione “Pagina Web completa” creerà, oltre a un file HTML, una cartella con lo stesso nome contenente tutti gli elementi grafici, gli stili e gli script della pagina. Uno svantaggio di questa opzione è la creazione di ingombranti file ausiliari. L’opzione “Pagina Web, file singolo” è più utile, infatti consente di raggruppare la pagina Web e tutte le relative risorse in un unico file con estensione .mhtml. Si apre in Chrome ed Edge, ma altri browser potrebbero dare problemi. Questa opzione non è disponibile in tutti i browser, ma se si installa l’estensione SingleFile (disponibile per la maggior parte dei browser), si potrà salvare l’intera pagina Web e il relativo contenuto multimediale come singolo file HTML perfettamente apribile in tutti i browser moderni.
Stampare su PDF. Per preservare il contenuto principale di una pagina, a eccezione dei menu e dei banner, l’opzione migliore è Stampa su PDF. Il file risultante potrà essere aperto in qualsiasi computer.
Con ciascuna di queste opzioni, è necessario assicurarsi che il testo principale che si desidera mantenere sia leggibile quando si apre il documento.
Un modo più semplice per salvare una pagina Web
I metodi sopra descritti richiedono tempo e affollano il disco rigido. Per maggiore praticità è possibile usare un servizio dedicato come Pocket (precedentemente Read It Later), wallabag o Raindrop.io. Funzionano tutti allo stesso modo: si invia un collegamento da cui il servizio recupera un documento con tutte le illustrazioni, ripulisce la pagina da eventuali elementi non necessari e la salva nella memoria di archiviazione online personale. Anche se la pagina originale viene eliminata o modificata, la versione desiderata rimarrà nell’archivio. Questi servizi consentono di raggruppare e ordinare i collegamenti, cercare testo nei contenuti e visualizzare le pagine salvate in qualsiasi dispositivo. Per i computer desktop sono disponibili estensioni su tutti i principali browser; per i dispositivi mobili c’è un’app.
Tutti questi servizi offrono un archivio “eterno” solo con un abbonamento premium: la comodità si paga. Detto questo, Wallabag è open source: è possibile installarlo sul proprio server senza pagare per servizi di terze parti o preoccuparsi della chiusura del servizio.
Anche alcune app per appunti possono salvare pagine Web complete. Tra queste vi è Evernote, in cui la funzionalità è chiamata “Web Clipper”.
Come salvare una pagina Web per altri utenti
Se non è necessaria solo una copia per sé stessi ma anche per altri, sarà necessario un servizio di archiviazione pubblico.
Il più noto è Internet Archive (archive.org) e la sua Wayback Machine. Altre opzioni includono archive.today (alias archive.is), perma.cc e megalodon.jp. Funzionano tutte secondo un principio simile: su richiesta dell’utente (o automaticamente) visitano le pagine Web e ne salvano una copia nei propri server.
Per richiedere l’archiviazione di una pagina Web, accedi a web.archive.org e immetti l’indirizzo completo nella casella Salva pagina ora. Dopo avere fatto clic su Salva, verrà visualizzata una finestra che descrive tutti i componenti caricati della pagina, seguiti da un collegamento permanente al sito nel corrispondente stato di conservazione. Un esempio: https://web.archive.org/web/20240918234814/https://www.kaspersky.com/blog. Il collegamento mostra sia l’indirizzo della pagina salvata che l’ora esatta di salvataggio, un’opzione perfetta a fini di archiviazione.
La registrazione a archive.org consente di gestire una raccolta di tali collegamenti, acquisire schermate dei siti salvati e scaricarne copie nello speciale formato di archiviazione Web WACZ.
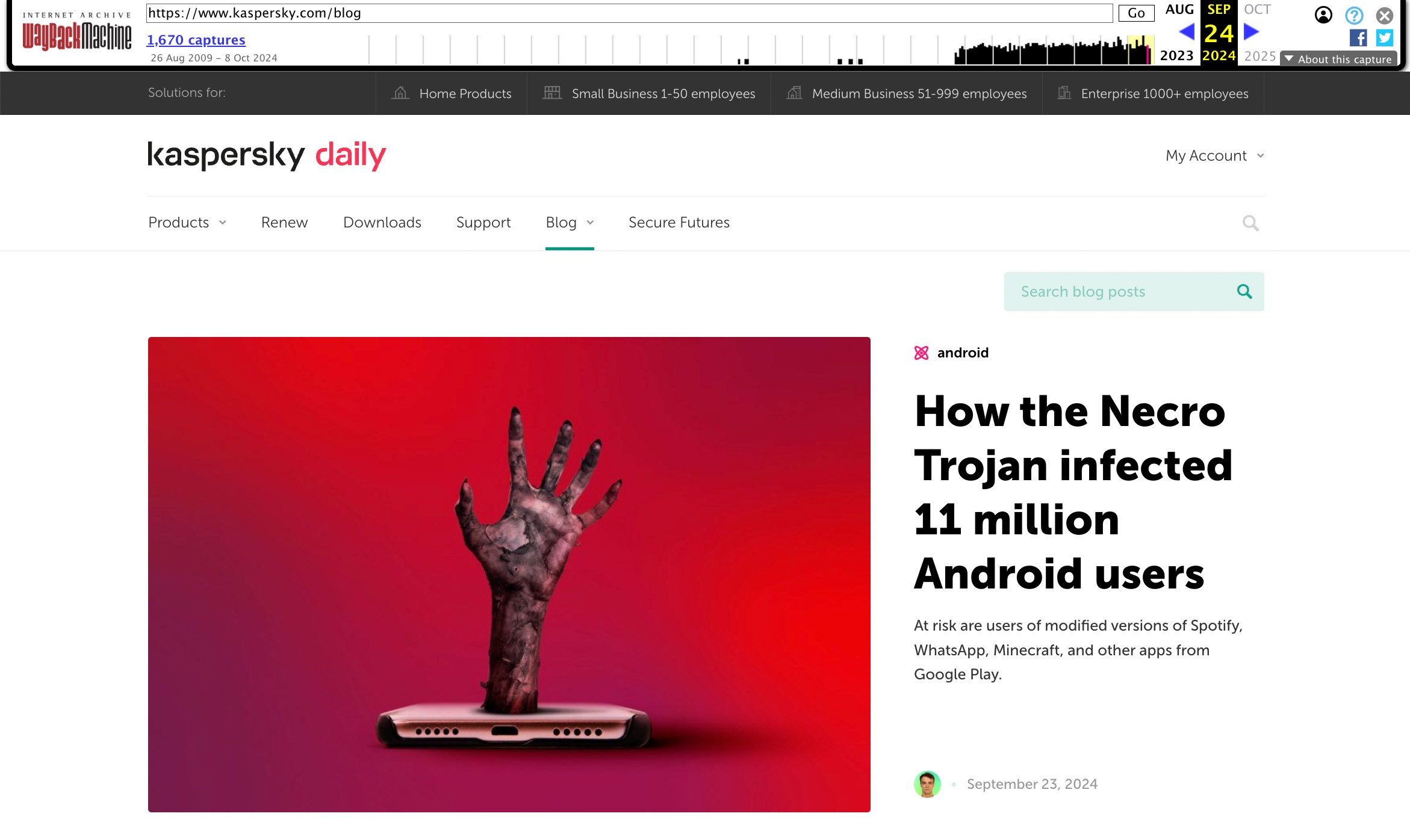
In archive.org è possibile visualizzare le versioni dei siti Web salvate in precedenza e salvare lo stato corrente di qualsiasi sito, come nell’esempio del nostro blog
Aprendo il collegamento all’archivio, verrà visualizzata la pagina salvata con un timestamp dell’acquisizione. Questa funzionalità è utile per tenere traccia delle modifiche nei siti Web: fluttuazioni di prezzi, aggiornamenti nelle descrizioni dei prodotti, news rivedute e corrette e informazioni eliminate. Quest’ultimo caso è particolarmente importante per ricercatori di temi storici e culturali che studiano su siti Web defunti. Qui sotto indichiamo un link a una delle prime versioni di GeoCities, un servizio di hosting Web un tempo popolare che molto prima dei social network consentiva di creare le proprie “home page”, esprimersi e trovare amici con interessi condivisi. È solo grazie alla Wayback Machine che possiamo vederlo oggi: il sito ha chiuso i battenti nel 2016.
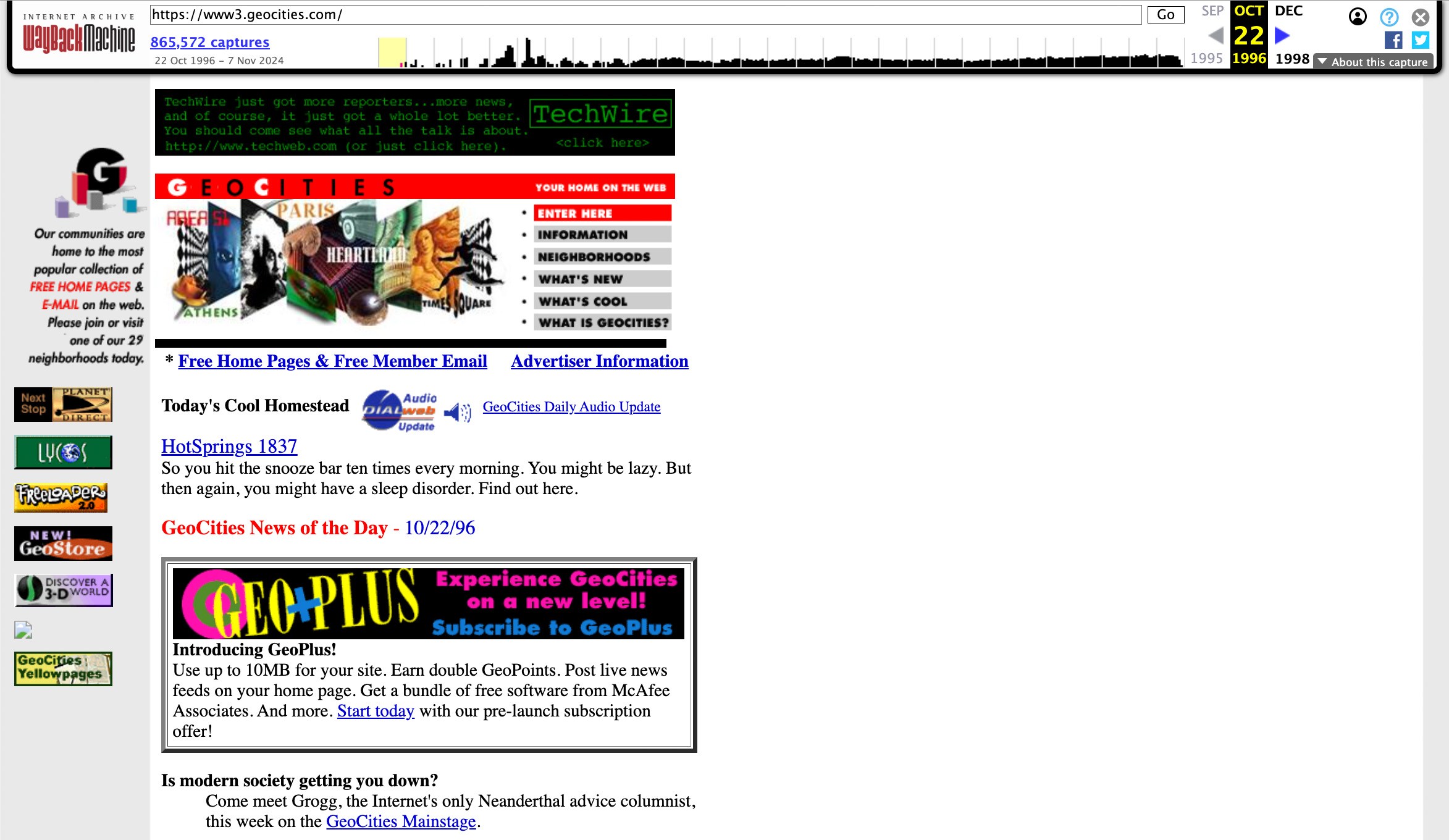
Un regalo per veterani: una delle prime versioni di GeoCities.com
Come trovare contenuto Internet eliminato o una versione precedente di un sito Web
Per visualizzare una versione precedente di qualsiasi sito Web:
- Apri archive.org.
- Immetti l’indirizzo completo del sito Web o di una pagina specifica nella casella accanto al logo e fai clic su Enter. Se l’URL esatto è sconosciuto, è possibile immettere il nome del sito Web o parole che lo descrivano correttamente.
- Seleziona il sito Web desiderato dall’elenco. I risultati mostreranno a colpo d’occhio quante copie del sito sono state archiviate e per quale periodo.
- Con il calendario è possibile selezionare la specifica copia salvata da visualizzare. Le date per cui è presente una copia salvata sono cerchiate: più grande è il cerchio, più copie sono state fatte quel giorno.
- Fai clic sulla data desiderata e ispeziona il sito salvato. Il caricamento di una copia dall’archivio potrebbe richiedere alcuni minuti.
- Il grafico del calendario sopra la copia del sito consente di passare alle copie precedenti o a quelle più recenti.
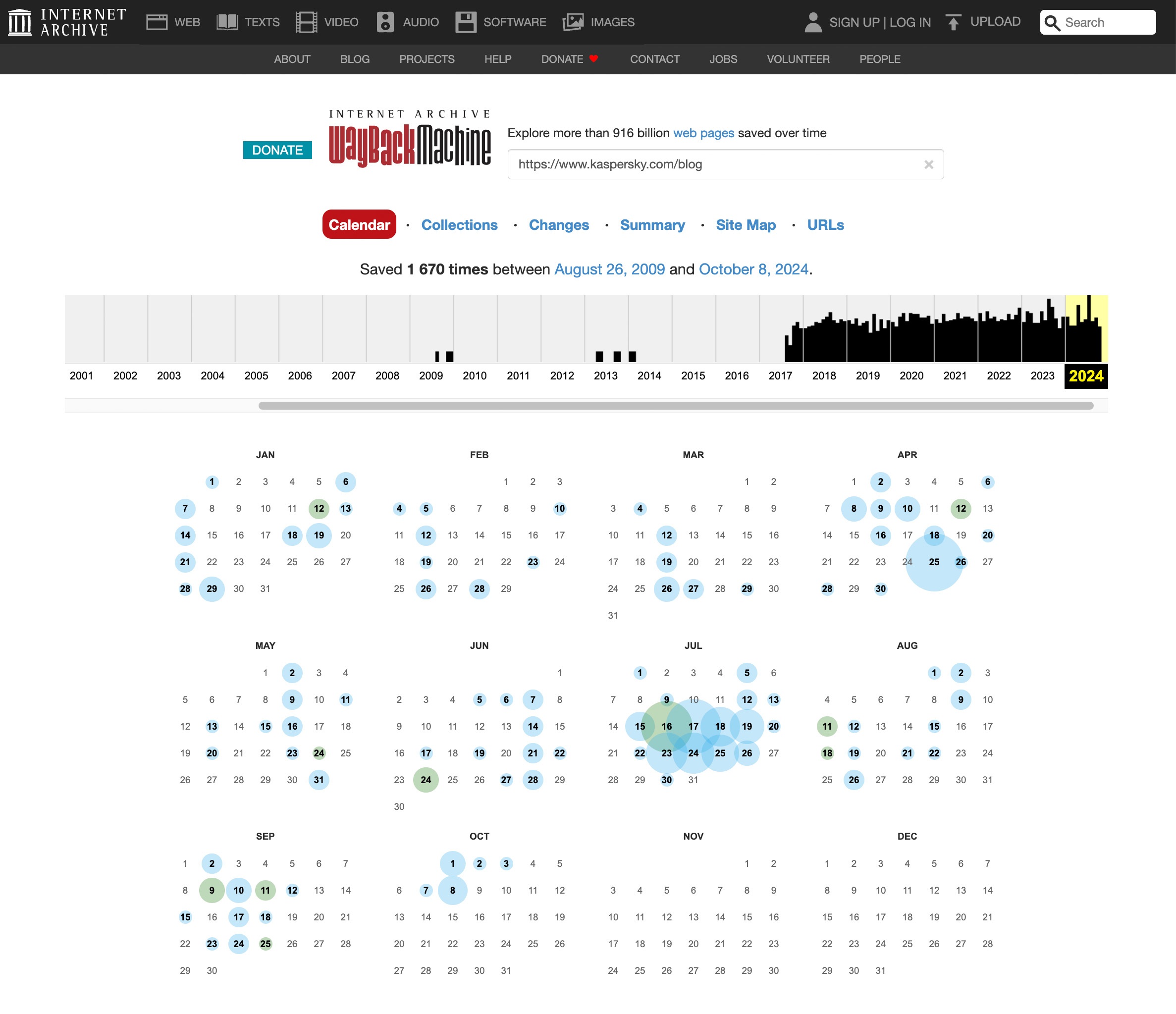
Come esplorare le versioni precedenti dei siti all’indirizzo web.archive.org
È possibile copiare il collegamento al materiale recuperato dalla barra degli indirizzi per accedere direttamente al sito archiviato, ignorando l’interfaccia di ricerca.
Cosa fare se archive.org non è di aiuto
Il funzionamento di archive.org prevede di poter soddisfare le richieste di escludere determinati siti dalla Wayback Machine provenienti da detentori di copyright e di altre parti autorizzate. Inoltre, il servizio non ha mai mirato a preservare l’intera rete Internet, quindi è possibile che una certa pagina non sia mai stata indicizzata. In questi casi si può provare a cercarla in altre capsule del tempo.
Archive.today (alias archive.is) non salva automaticamente le pagine, ma lo fa solo su richiesta degli utenti. Tra le altre cose, fa a meno di seguire le istruzioni per i robot di ricerca (robots.txt) e significa che l’archivio contiene documenti che non sono disponibili nella Wayback Machine.
Un altro importante progetto di archiviazione Web è perma.cc, creato da un consorzio di grandi biblioteche mondiali. Tuttavia, è gratuito solo per le organizzazioni partecipanti. I singoli utenti possono sottoscrivere un piano a pagamento, con prezzi basati sul numero di link archiviati.
Una potente alternativa agli archivi specializzati è il contenuto memorizzato nella cache dei motori di ricerca. Per indicizzare qualsiasi pagina Web, i motori di ricerca ne recuperano il testo, quindi è possibile trovare una versione grezza ma leggibile di quasi ogni pagina. Per molto tempo la cache di Google è stata la più accessibile, ma all’inizio del 2024 il colosso della ricerca ha rimosso il collegamento diretto alla propria cache dai risultati di ricerca. Il servizio funziona ancora, ma accedervi direttamente è molto difficile.
Pertanto, è preferibile usare estensioni del browser che semplifichino l’utilizzo degli archivi Internet. Ad esempio, se un collegamento reindirizzerà a una pagina eliminata o a un sito Web defunto, l’estensione Web Archives reindirizza direttamente a una copia archiviata di questa pagina all’indirizzo web.archive.org, archive.today o perma.cc, oppure mostrerà un versione memorizzata nella cache di Google, Bing o Yandex.
Come salvare i dati da altri servizi in linea
Oltre alle pagine Web, sono disponibili molti altri servizi online, come album fotografici, servizi di appunti e social media, che contengono dati che si potrebbero voler salvare. Naturalmente, i suggerimenti d’uso dipendono dai diversi tipi di dati e dai servizi specifici, ma per comodità abbiamo raggruppato tutte le istruzioni correlate sotto il tag “backup”. Le informazioni sulla creazione di backup sono disponibili per:
- Notion
- Telegram
- App di autenticazione 2FA
- Altri servizi
Senza dimenticare l’importanza di salvaguardare i backups contro ransomware e spyware!

 Consigli
Consigli