 AI
AI
Molte persone hanno già iniziato a utilizzare le reti neurali generative e lo fanno regolarmente, anche al lavoro. Ad esempio, quasi il 60% degli americani impiega regolarmente ChatGPT e altri sistemi analoghi (e non sempre con l’autorizzazione della propria azienda). Tuttavia, tutti i dati coinvolti in queste operazioni, sia le richieste dell’utente che le risposte del modello, vengono salvati nei server di OpenAI, Google e così via. Per le attività per cui questo non è accettabile, non devi necessariamente smettere di usare l’IA: con un impegno minimo (e senza spendere un capitale) puoi eseguire la rete neurale in locale, sul tuo computer (anche laptop).
Minacce cloud
Gli assistenti IA più noti vengono eseguiti sull’infrastruttura cloud di grandi aziende. Il modello è efficiente e veloce, ma i dati che elabora potrebbero essere accessibili sia al provider del servizio IA che ad altri interessati completamente indipendenti, come è successo l’anno scorso con ChatGPT.
La gravità della minaccia rappresentata dagli incidenti di questo tipo dipende dal modo in cui si utilizzano gli assistenti IA. Se ad esempio stai generando alcune graziose illustrazioni per delle fiabe che hai scritto o se hai intenzione di chiedere a ChatGPT di crearti un itinerario per il prossimo weekend, è improbabile che una fuga di dati possa avere gravi conseguenze. Tuttavia, se nella conversazione con un chatbot vengono incluse informazioni riservate (dati personali, password o numeri di carte bancarie), è necessario evitare l’eventualità che si verifichi una divulgazione nel cloud. Per fortuna, è possibile prevenire questo tipo di eventi in modo relativamente facile prefiltrando i dati come spiegato in questo post.
Nei casi in cui è imperativo garantire la riservatezza di tutta la corrispondenza (ad esempio per le informazioni mediche o finanziarie) o se il prefiltraggio potrebbe non essere del tutto affidabile (ad esempio quando è necessario elaborare grandi volumi di dati che nessuno potrà visualizzare in anteprima e filtrare), l’unica soluzione è spostare l’elaborazione dal cloud a un computer locale. È ovvio che eseguendo ChatGPT o Midjourney offline molto difficilmente potrai ottenere i risultati che desideri. Sono tuttavia disponibili altre reti neurali, in grado di funzionare in locale e di assicurare un livello qualitativo equivalente, con un minor carico sulle risorse di elaborazione.
Che tipo di hardware è necessario per eseguire una rete neurale?
Probabilmente avrai sentito dire che per lavorare con le reti neurali sono necessarie schede grafiche super potenti. In pratica, però, non sempre è così. Modelli di intelligenza artificiale diversi, a seconda delle loro specifiche, possono avere requisiti differenti in termini di componenti del computer come RAM, VRAM, unità e CPU (non è importante solo la velocità di elaborazione, ma anche il supporto del processore per determinate istruzioni vettoriali). La capacità di caricare il modello dipende dalla quantità di RAM diaponibile e le dimensioni della “finestra di contesto”, ovvero la memoria della conversazione precedente, dipendono dalla quantità di VRAM (Video RAM) diaponibile. In genere, con una scheda grafica e una CPU poco potenti, la generazione avviene a un ritmo rallentato (da una a due parole al secondo per i modelli di testo). Pertanto, un computer con una configurazione minima è aaìdatto solo per familiarizzare con un particolare modello e valutarne l’idoneità di base. Per un uso quotidiano completo, dovrai aumentare la RAM, aggiornare la scheda grafica o scegliere un modello IA più veloce.
Come punto di partenza, puoi provare con un computer di quelli considerati relativamente potenti nel 2017: processore non inferiore a Core i7 con supporto per le istruzioni AVX2, 16 GB di RAM e scheda grafica con almeno 4 GB di VRAM. Per gli appassionati di Mac, i modelli che funzionano con il chip Apple M1 e versioni successive vanno bene e i requisiti di memoria sono gli stessi.
Quando si sceglie un modello IA, è innanzitutto necessario familiarizzare con i requisiti di sistema. Una query di ricerca come “requisiti nome_modello” ti aiuterà a valutare se vale la pena o meno scaricare questo modello, tenendo in considerazione l’hardware a tua disposizione. Per saperne di più sull’impatto delle dimensioni di memoria, CPU e GPU sulle prestazioni dei diversi modelli, sono disponibili alcuni studi dettagliati come questo.
Buone notizie per chi non ha una dotazione hardware particolarmente potente: esistono alcuni modelli di intelligenza artificiale semplificati, in grado di eseguire attività pratiche anche sui sistemi hardware meno recenti. Persino con una scheda grafica di base e poco potente, è possibile eseguire modelli e avviare ambienti utilizzando solo la CPU. A seconda delle attività, possono anche funzionare in modo accettabile.
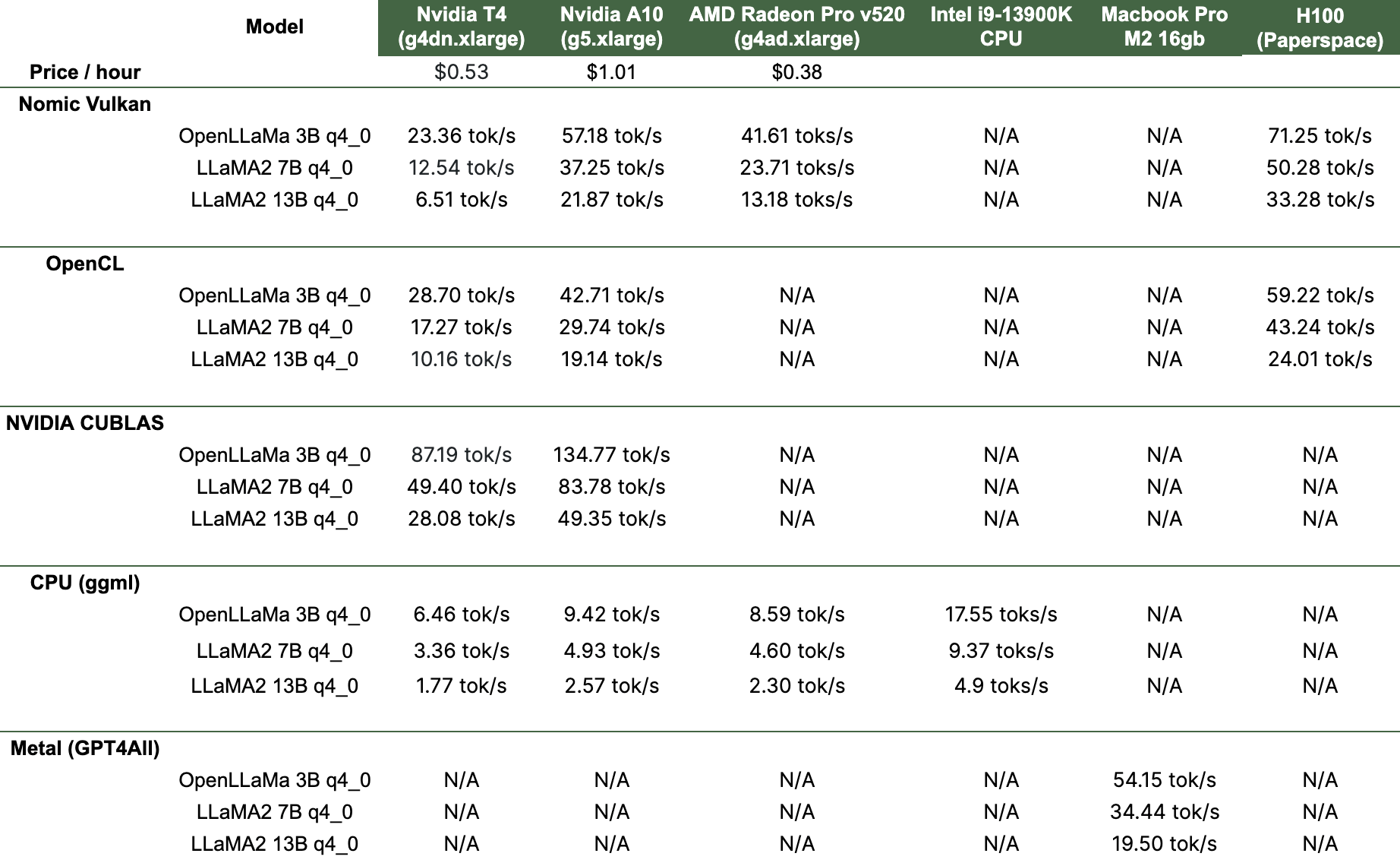
Esempi di come funzionano varie build di computer con alcuni popolari modelli linguistici
Scelta di un modello IA e vantaggi della quantizzazione
Oggi è disponibile un’ampia gamma di modelli linguistici, molti dei quali hanno però applicazioni pratiche limitate. Ad ogni modo, esistono anche alcuni strumenti di intelligenza artificiale facili da usare, pubblicamente disponibili e adatti per attività specifiche, che si tratti della generazione di testo (come Mistral 7B) o della creazione di frammenti di codice (come Code Llama 13B). Pertanto, quando si sceglie un modello, è opportuno restringere la selezione a pochi candidati idonei e quindi assicurarsi che il computer disponga delle risorse necessarie per eseguirli.
In qualsiasi rete neurale la maggior parte della memoria è impegnata in funzione dei pesi, ovvero i coefficienti numerici che descrivono il funzionamento di ciascun neurone presente nella rete. Inizialmente, durante il training del modello, i pesi vengono calcolati e archiviati come numeri frazionari con un elevato livello di precisione. L’arrotondamento dei pesi nel modello addestrato consente comunque di eseguire lo strumento IA su normali computer riducendo solo leggermente le prestazioni. Grazie a questo processo di arrotondamento, chiamato quantizzazione, le dimensioni del modello possono essere ridotte considerevolmente: invece di 16 bit, ogni peso potrebbe utilizzare 8, 4 o anche solo 2 bit.
In base a una attuale ricerca, a volte un modello di maggiori dimensioni con parametri ed quantizzazione più elevati può dare risultati migliori rispetto a un modello con memorizzazione precisa del peso ma parametri inferiori.
Con queste conoscenze, puoi esplorare il mondo dei modelli linguistici open source, ovvero la classifica Open LLM. In questo elenco gli strumenti IA sono ordinati in base a diverse metriche relative alla qualità della generazione. Inoltre, utilizzando i filtri puoi escludere i modelli troppo grandi, troppo piccoli o troppo accurati.
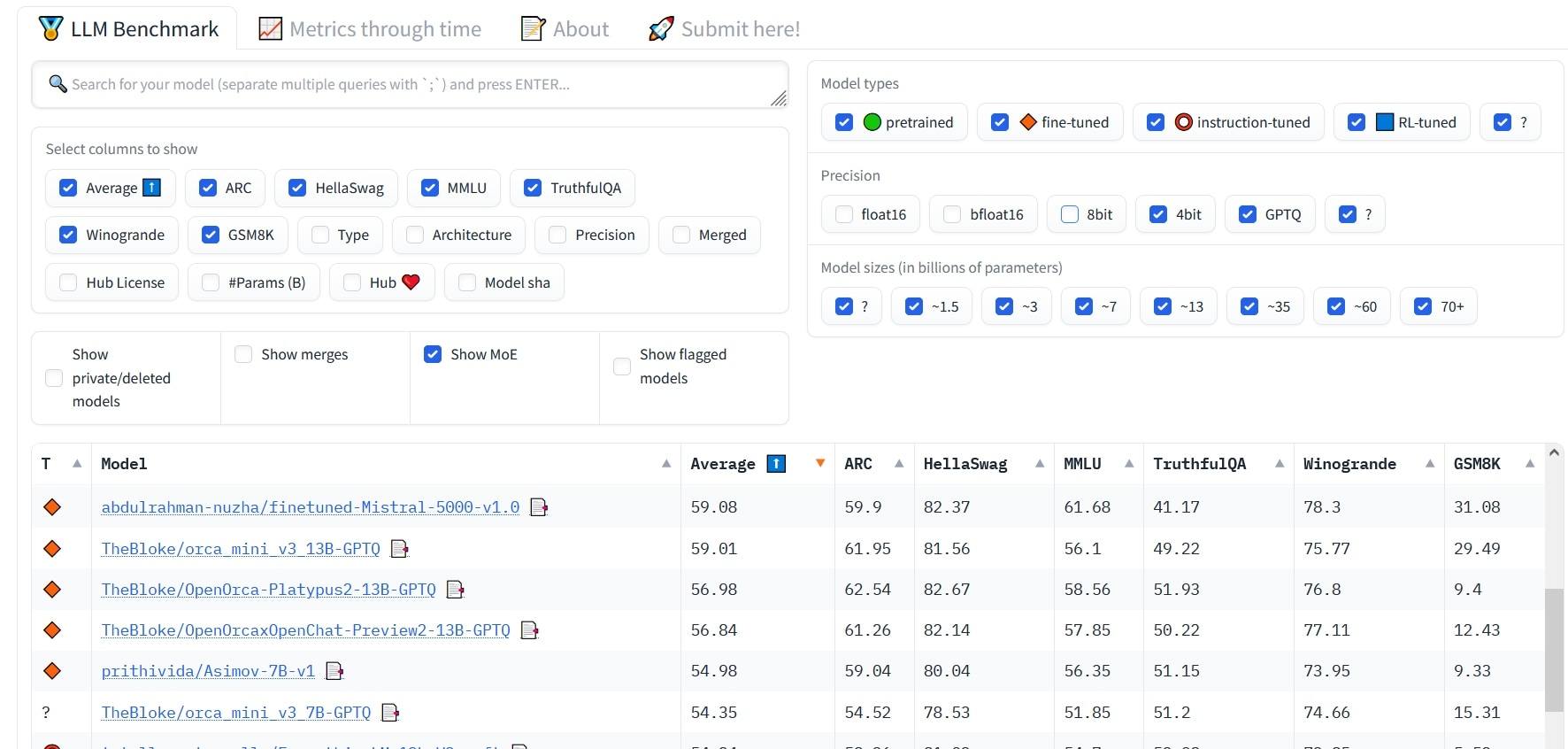
Elenco dei modelli linguistici ordinato applicando i filtri
Dopo aver letto la descrizione di un modello e aver verificato che sia potenzialmente adatto alle tue esigenze, puoi testarne le prestazioni nel cloud utilizzando Hugging Face o i servizi Google Colab. In questo modo eviterai di scaricare i modelli che producono risultati non soddisfacenti, risparmiando tempo. Se la prova iniziale del modello ti soddisfa, puoi vedere come funziona in locale.
Requisiti software
La maggior parte dei modelli open source viene pubblicata su Hugging Face. Tuttavia, scaricare questi modelli nel computer non è sufficiente. Per eseguirli bisogna installare un software specializzato, come LLaMA.cpp o, per semplificare ulteriormente le cose, il suo “wrapper” LM Studio. Quest’ultimo consente di selezionare il modello desiderato direttamente dall’applicazione, scaricarlo ed eseguirlo in una finestra di dialogo.
Un altro modo “pronto all’uso” per utilizzare un chatbot in locale è GPT4All. In questo caso la scelta è limitata a una decina di modelli linguistici, la maggior parte dei quali funziona anche su computer con appena 8 GB di memoria e una scheda grafica di base.
Se la generazione risulta troppo lenta, potrebbe essere necessario passare a un modello con un livello di quantizzazione ancora più basso (2 bit anziché 4). Se la generazione viene interrotta o se durante l’esecuzione si verificano errori, il problema è spesso la memoria insufficiente: vale la pena cercare un modello con parametri inferiori o, di nuovo, con un livello di quantizzazione più basso.
Molti modelli disponibili su Hugging Face sono già stati quantizzati con vari gradi di precisione. Tuttavia, se finora nessuno ha quantizzato il modello che ti interessa con la precisione che ti interessa, puoi farlo tu utilizzando GPTQ.
Questa settimana, è stato rilasciato in versione beta un altro promettente strumento: Chat With RTX di NVIDIA. Il produttore dei più richiesti chip IA ha rilasciato un chatbot eseguito in locale in grado di riassumere il contenuto dei video di YouTube, elaborare set di documenti e molto altro, a condizione che l’utente disponga di un PC Windows con 16 GB di memoria e di una scheda grafica NVIDIA RTX Serie 30 o 40 con almeno 8 GB di VRAM. Alla base del suo funzionamento si trovano gli stessi modelli LLM Mistral e Llama 2 di Hugging Face. Una potente scheda grafica può senza dubbio migliorare le prestazioni della generazione, ma la beta attualmente disponibile è stata giudicata dai primi tester piuttosto ingombrante (circa 40 GB) e difficile da installare. In futuro, tuttavia, Chat With RTX di NVIDIA potrebbe diventare un utilissimo assistente IA con cui interagire in locale.
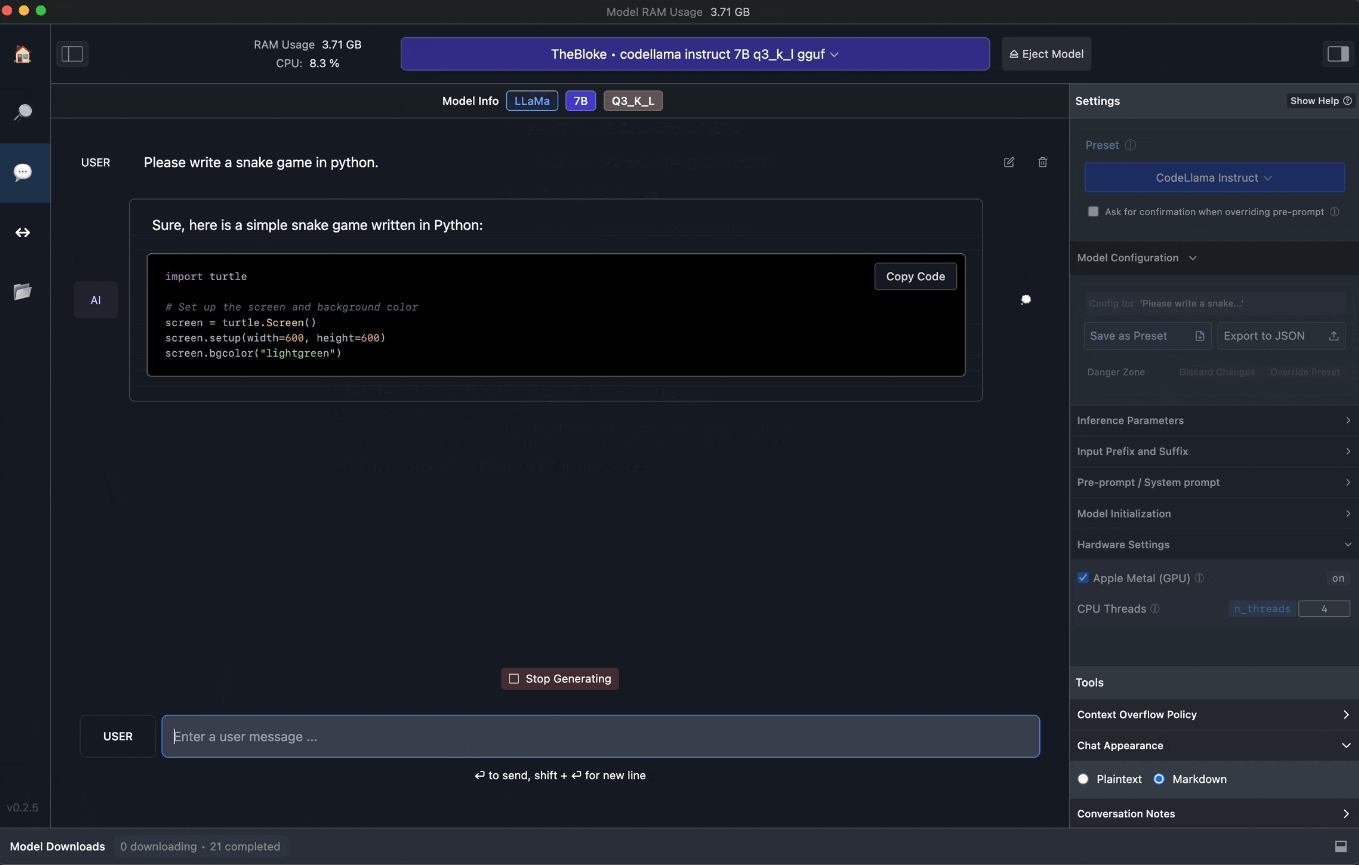
Il codice per il gioco “Snake”, scritto dal modello linguistico quantizzato TheBloke/CodeLlama-7B-Instruct-GGUF
Le applicazioni sopra elencate eseguono tutti i calcoli in locale, non inviano dati ai server e possono essere eseguite offline, in modo da poter condividere con loro informazioni riservate. Per essere completamente protetti contro le fughe di dati, tuttavia, è necessario garantire la sicurezza non solo del modello linguistico adottato, ma anche del computer. Ed è qui che entra in gioco la nostra soluzione di protezione completa. Come confermato nel corso di alcuni test indipendenti, Kaspersky Premium non interferisce minimamente con le prestazioni del computer. E questo è un importante vantaggio quando si lavora con modelli IA eseguiti in locale.

 Consigli
Consigli